Dunjunz & Dragons
- 2020-06-22 - Wait, there's more!
- 2017-07-28 - And we're done!
- 2017-07-23 - I can still remember
- 2017-06-26 - The icing on the world
- 2017-06-18 - Beta 1
- 2017-06-11 - Something worth trying for
- 2017-06-01 - Need better title
- 2017-05-14 - Careful, Eugene
- 2017-05-02 - I don't like Tuesdays
- 2017-04-29 - Objects (back) in motion
- 2017-04-19 - Just the wrong shade of pink
- 2017-04-18 - Serious business
- 2017-04-17 - Monster mash
- 2017-04-15 - Tooling up
- 2017-04-12 - Less ancient history
- 2017-04-10 - Ancient history
Ancient history
Long ago, deep in the mists of time (the late 1980s), a new game "became available" for the BBC Micros at school. It wasn't anything like Elite or Dare Devil Dennis. Multiple people played simultaneously, but it wasn't Dogfight. New! Exciting!
The game was Dunjunz, and four (count 'em) people played at once, all crowded around the Micro's keyboard. Not only that, but each player got their own window on the world. So four friends (well, this was secondary school, so let's just say people who didn't actively avoid each other) could cooperate to fight monsters and solve puzzles. Or, more likely, shoot each other.

Dunjunz (by Julian Avis for Bug Byte) is basically a home computer1 version of Gauntlet; avoiding the name to avoid the lawsuit as was typical back then, but also with a different take on the presentation. As previously mentioned, each player gets their own window. This greatly enhances gameplay in my view: everyone can go off and do their own thing without being constrained by the position of the others.
Apparently there was also a back story involving a great demon with the implausible name of "Mackscrane", but for some reason I never read the inlay.
FSVO "home" - the BBC Micro was notoriously expensive. There was an Electron version, though.↩
Anything you can do
Nothing like this existed for the Dragon, so obviously I had to write my own version. I spent a lot of time on this (ah, school days, with so much time free to work on things by the simple expedient of not doing your homework): designing graphics, making levels, coding it all up in assembly language then finally losing the disk. Such is life. Here's where I remember getting:
- Hi-res black & white graphics
- Two players, joystick controlled
- 16x16 tiles
- Players moved around tile by tile on the map
- No monsters!
- But there were energy drainers, and they did drain your health, and you could shoot them
Well, it's possible that, had I labelled my disks more clearly, that might have developed into a full game. But to be honest it wasn't very good: my art skills sucked (they still do), there were no animations, and let's face it, two players just isn't enough.
Obviously I wouldn't be writing this if that were the end of the story.
Less ancient history
In 2006, James McKay released Glove, a Gauntlet clone for the Dragon and Tandy CoCo. It's pretty excellent. Full screen scrolling, lots of monsters, all the usual Gauntlet stuff. You could even buy it on tape. And you should! It's available from Cronosoft.
But it ain't Dunjunz.
So a few years ago (and to really put this into context, that's another eight years later), I started tinkering again. After all, I've got a pretty good emulator. I've got a serviceable cross-assembler. And in theory I can even stop working when I get home so that I have the time.
Mostly what I did was prove to myself I could have a map and have things wandering around that map. This also forced a few decisions about the constraints a new approach would have to work within.
Invested with decisiveness
The most obvious one is the display. The BBC Micro version runs in "MODE 2", which gives 320x256 pixels (with horizontal resolution halved) in 8+8 colours. That "+8" is a set of values that flash between two of the base colours giving a sort of free "animation".
In Dragon graphics modes, you can have two colours in high-resolution, or four colours with halved horizontal resolution (that is, without trickery that takes up far too much CPU time). My original effort used black & white, but after a bit of experimenting, tiles were a lot more recognisable in colour even with the reduced horizontal resolution.
Dunjunz tiles are 16x12 pixels. In order to fit four windows 8 tiles wide and 8 tiles high onto the screen, that requires 256x192 pixels. We have this on the Dragon - hooray! But only this. There would then be no room for player stats, nor any separation between the player windows.
That would not be the same experience. You need to be keeping an eye on your health, and the other stats (weapons, armour, speed, keys) are nice to see. So we need to drop the tile size. This introduces a complication: a 16 pixel wide tile is really easy to draw, as it's just two bytes. An 8 pixel wide tile - even easier to draw - just isn't enough to represent anything useful (and besides, player windows would become tiny). Any other size, and adjacent tiles will need shifted by some number of pixels as they won't be byte aligned.
A very early optimisation is to never perform the graphics shifting on-the-fly. It's a very slow process. The best approach is to store copies of every tile shifted by every number of pixels required. The halved horizontal resolution means that's a maximum of four copies of the tile (i.e., data shifted 0, 2, 4 and 6 pixels).
Using a tile size of 12x9, only two copies are required. This is also exactly the same scale factor as the difference in screen resolutions, so this was the obvious choice. It also means I can't just copy the graphics directly from the BBC Micro version, as I'm dropping both the number of colours and their size.

At least it'll only be the design I'm ripping off!
Tooling up
Every good workman needs tools to blame, and there is some automation necessary here. First off, maps. I have no idea how the map is going to be best represented in memory, so rather than hard code it and have to edit it later, some sort of design tool is required.
Dunjunz maps all2 have a size of 32x48 tiles. Representing what tiles appear where in a fixed grid of that size is something a text file is really good at, so all I have to do is parse one.
One short Perl script later, and I have a tool that will slurp in a text file and emit some useful assembler source. Stone walls are represented with a hash ('#'), floor with a space and other types of item basically using representations borrowed from Nethack. Keys need to be matched to doors, so after the 32 characters representing the width of the map, a list of identifiers present on that line is included.
Next, actually getting the graphics into a usable form. I can use the GIMP to create them (I know the GIMP developers have higher aspirations, but I pretty much still just use it as a pixel editor) and leave me with a PNG, but that's no good for my code. Thankfully I've already tackled this problem, so I just adapt the sprite compiler from my Horizontal Scroll Demo. This can generate both the byte-aligned and shifted versions of the tiles, and for the moment gives me very fast rendering at the expense of space. When there's more actual game, I may have to reconsider that tradeoff.
In pretty short order, I can knock out some code that uses the map data with the graphics data and renders some player windows. Progress! Right now it seems to me that a good way to do this is to maintain a buffer per player reflecting what their window is showing, and if anything changes on the map itself, this change can be reflected on-screen, then updated in the buffer.

The final level is still a bit of a mystery. I'm still searching for a clue.↩
Monster mash
So I can draw bits of a map, I can even add some kludgy code to let me pan around it (and interpret random memory as map data in the process!). The per-player buffer means that whenever I change where the player's window is pointing, all the differences are reflected on screen without any extra code. But my younger self never did get as far as adding monsters. Present me obviously thinks this is a good time for a diversion to see how that might work.
Littered around the map are "trapdoors", through which monsters ("Bashers", it seems they are called) enter the game. Every time you kill a monster, another one is spawned. The monsters themselves don't have any intelligence in the original game: they shuffle along in one direction until they encounter an obstacle. If that obstacle happens to be a player, they hit the player for some damage, but either way they then turn around and head off in another random direction.
Great! Artificial Dumbness is much easier than the alternative. Some more decisions about the map representation come about: it'll be really useful if any tile that should block movement is trivially identifiable. For now I decide that the last few tile IDs should be "blocking", therefore any ID in the map greater than a certain value can be detected and cause the monsters to turn around.
I also need to know where to spawn them: the trapdoor tiles are in the map, but scanning it each time to find one is really inefficient. So the map parser gets a tweak to emit a separate list of trapdoors. My monster spawning routine can just move through this list picking the next one each time, and monsters will distribute themselves nicely through the map.
As for changing direction, I decide to just maintain a "next direction" value and advance it each time a decision is required for a monster. As the decisions are distributed across all the monsters, this will look pretty random when just watching one of them.
Just to prove the movement algorithm works, I quickly make the monsters appear directly in the map as tiles. Et voilà!
And then I do nothing for about three years. Typical!
Serious business
To get the gameplay right, a lot of seemingly trivial observations about the original need to be noted and borne in mind. Some will be important, and may give hints about how things work underneath (I'm not disassembling this game to find that out exactly). Unfortunately the only way to do this is to play it a lot. Hardship. So, in no particular order:
No tile is ever clipped at the edge of a window. Sprites disappear as soon as they move beyond the edge.
All items seem to be redrawn all the time. Thus, you see keys even where a player has died (good), and sometimes the player's sprite is rendered invisible by a trapdoor or energy drainer (bad).
Bashers do (10 - armour) damage when they hit. If player moves into basher, 1 damage is done whatever the armour value.
PvP shots always do damage based on level, armour value has no effect.
Best guess is that bashers have 9 HP: Barbarian's level 9 axe can one-shot them.
Bashers don't walk over the bones of dead players. Bones from player 1 defend players 2-4 from bashers and player shots. Bones from player 2 only defend players 3 & 4, and so on. Basically, bones are still a player sprite, and collisions are tested in player order.
Player keys are tested in order: Magic, Up, Down, Right, Left, Fire. Only one is active at a time.
All players are frozen while casting magic, and magic only activates once a player is centred in their tile.
Keys stack. That is, if a player dies on top of a key, the map position will contain two keys. Sitting on top of a pile of keys rotates them through your inventory.
Deep thought
That last point is pretty key (ahem). One map position can contain multiple items. As it happens, there's been some discussion of this on the StarDot forums. While I'm still not personally going to dive into disassembling the game, there's some useful information to take away here.
It seems that BBC Micro Dunjunz doesn't keep a complete map in memory. Instead, a packed bitmap represents walls (any blocking object, I think, including doors), and it constantly iterates over the complete list of objects, both for drawing and collision detection. Possibly it does both these things in one pass, evaluating collisions before drawing: if you're going to do one, you may as well do the other.
There is also a second packed bitmap indicating tiles with something interesting in. Presumably this is used to reduce the number of times the object table needs to be scanned.
I'm not sure I want to do this. To detect a player-monster collision, you still need to traverse the monster list (how many monster? Good question!) every time a player moves. Monsters also bump off each other, so that's another O(N²) set of comparisons right there. Attempting to move into any wall must cause it to scan the door list (20 doors). I see no reason not to optimise all this. Premature optimisation is where all the good shit comes from; I'm pretty sure that's the saying.
Using a single byte to track the contents of each position, a 32x48 map takes up 1.5K. That seems a reasonable amount to throw away if we only have to examine one memory location to check for collisions or items. But how can multiple objects share a space? How does this help check for monster collisions (or player collisions when we come to move the monsters)?
The answer to stacking is to make the object table a linked list. Any map position with an object has the object's ID in the map. Each object contains a link byte that links to any other objects in the same stack. An important thing to remember here will be that when swapping a key from the player's inventory with a key in the map, the inventory key has to go to the bottom of the stack. If it were just swapped, and there were more than one key on the tiles, you'd never be able to pick one of them up.
Anything I can't eat
Quite a lot of the map isn't an item: it's wall or floor. So having those in the object table would be dumb - they're better represented with special values in the map. While we're saying there are special values at all, let's extend that: any normal tile that ordinarily blocks movement (so, including doors) can get a special value too. Some special numbers are really easy to test for: zero is one of them. Let's make the floor zero (that feels right anyway). Negative values are also easy to test for, so make the blocking tiles negative. Any non-zero positive number can be considered an index into the object table.
And how about collisions? Well for player-monster or monster-monster collisions, updating the map with another special value when a monster "occupies" a tile can indicate immediately that we either need to dock the careless player's health or bounce an approaching monster. Just need to be careful to restore the original value when the monster moves off.
Can we do this for players too? Well, yes, probably, but that "feature" where different bones protect different sets of players from attack is a pretty obvious artifact of explicitly comparing moves against player locations, in order. I think at least to begin with, I'd like to keep that quirk. Four compares per monster; maybe not too great a hardship.
Just the wrong shade of pink
Too much real work. Time for a distraction!
Ok, it's still pretty important, but this could have been put off. Sometimes you're just too drunk to think about data structures. So let's revisit the graphics.
It occurred to me that blue is a little closer to the black background of the original than bright green, so just to experiment, I tweaked the tile compiler to swap blue & green. I'm quite pleased with the results!
I think when I originally positioned those player windows, I imagined there would be no way to get the player stats, score, etc. down the side as it is in the BBC Micro version. The Electron version just lists all that as text below the play area; I imagined that might be necessary.
But if you don't try, you don't find out, so I've broken out the GIMP again, this time just to piece together a play screen and indicate how hard it would be to draw the individual elements.

The off-colour backgrounds around the stats areas on the right hand side are to indicate byte boundaries. It all fits! All in all, this should end up looking a lot better than I thought it might.
Objects (back) in motion
Back to the code, and I've spent some time getting the monsters back in.
A simple state machine controls them, and they're always doing one of:
- Deciding on a direction to move
- Trying to move, if blocked, go back to picking a direction
- Moving: rendering successive offset monster sprites
- Landing on a new tile: update position
With some extra states for when a monster is moving to a different room: drawing the offset sprites would overwrite the viewport border, so skip the drawing stage in this case. A lot of the state machine code should be reusable for player sprites too, when they finally make an appearance.
That "if blocked" condition turned out to be trickier than I'd thought. If two monsters move into the same square (possible in the original, and possible here), I was ending up not properly undrawing one of them, dropping little monster turds all over the place. So for now at least I've abandoned the idea of dropping a monster marker on the map, and instead going for that O(N²) approach of comparing an intended movement against all other monster positions.
I'm also handling undraw by always drawing all items, and just rendering a blank tile if there is no item on a square the monster is moving from.
As it happens, this doesn't seem to have slowed things down too much:
Nippy! Far too fast, in fact. Hopefully that will translate into being just right when players arrive to do their thing.
As you can see in the video, I've also done a chunk of work getting the status windows in place: that's not a static prototype, it's all being drawn dynamically, and can be updated when necessary. You can also see some player sprite graphics - only a couple so far, the others being unflatteringly portrayed by monster sprites.
The downside to the extra sprites is that I'm running out of memory. I've already strayed above the 32K line, making this Dragon 64 only. I don't see it maxing out 64K, but I had other plans for that extra RAM, and I'd still like the main game to fit into a '32 (after all, the Beeb version ran on a 32K machine, and 12K of that was eaten by the graphics screen!).
It's probably time to start thinking of reducing those dynamic tile graphics down to simple bitmaps. They'll be slower to draw, but it'll free up a lot of RAM.
I don't like Tuesdays
A quick update that nonetheless follows a fair bit of progress. The Bank Holiday weekend has proved quite useful:
- Players appear on the map!
- They can move!
- They can pick up items
- Items score points, boost stats
- Energy drainers drain health
- Moving into a monster does 1 damage
- A monster moving into a player does (10-armour) damage.
Implementing player damage caused a bit of head scratching. As I store the health as BCD (Binary Coded Decimal) to ease drawing it to screen, I can't just use binary subtraction, and yet the 6809 instruction, DAA, only adjusts for BCD following additions, and I need to subtract. There must be a more clever way, but for now I'm just going to add (100-value), decimal adjust, then compare the result to the initial value. If it's higher, the subtraction went below zero, and the player is dead.
No players are yet dying for this cause: they just carry on wandering around with zero health.
I've also transformed the tiles into simple bitmaps. This does have a speed penalty, but it's not currently noticeable; having unrolled the tile drawing routine completely, it's probably as fast as it's likely to get. Player and monster sprites are still compiled for now, as they are drawn more regularly: hopefully they can stay that way, and I can keep everything else within 32K.
Player 4's sprite set is complete. I've drawn a lot of vertical animation frames for players, but the horizontal ones prove really difficult. The horizontal resolution is halved, and the BBC original had more pixels and more colours to indicate detail. Low resolution sprite work is quite an art, and I don't really have the eye for it, so it probably took me many times longer to do, but the end result looks pretty neat. I guess there are only so many combinations a few pixels can end up in, so eventually even a crap artist like me will hit on something good enough.
Only three more players to go... and to be honest, I don't like my monster sprites any more, so they'll need some attention.
Hopefully the next contrived entry title can be something about shooting things down.
Super bonus video special update wow
A bit more pixel work tonight, and I have all the players fleshed out. Rejigged the monster sprites too. Time for a video!
Compressing the level data, I'm now within 240 bytes of the top of (32K) RAM, so some more deep thought is going to be required soon.
Careful, Eugene
Long time since the last update, but I've not been (completely) idle. Here, have a video:
As you can see, a lot of gameplay elements are now here:
- Collect keys, open doors
- Shoot monsters
- Shoot energy drainers
- Shoot each other
- Raise the dead!
- Level... two?
Actually, all the levels are present, and for that I've got David Boddie to thank. During the discussion about level formats on stardot mentioned previously, David linked to a set of Python tools that did useful things with the data from the Electron tape version of the game. The BBC Micro disk version has levels in exactly the same format, so I was able to write my own Perl tools based on his work to convert them all into my custom format.
That's 24 levels all in 32K. Actually it's 25: the last level isn't available as a separate file (presumably because it contains the chalice), and the only reference I have for that is some screen captures and videos on the web.
About that 32K. I was scraping so close to the limit that I had to bite the bullet and convert all the player & monster sprites to tiles. That's saved me a lot of space - I've got more than 8K left to play with. And the performance penalty? Well, the video above has a delay loop in it to slow things down and it's still too fast: I think this is going to be OK.
Lots of finessing still required. The main one for me right now is that player shots aren't working as they should yet: it's possible to walk into them and shoot yourself. The way they're dispatched makes the player sprite flicker too.
But it's looking very much like I'll have something playable to show by the time of the Cambridge meet-up in June. Oh, didn't I say? Yes, some people from the Dragon Archive Forums have arranged a meet on the 3rd of June in Cambridge (that's the UK one, I can't even spell Massachusetts). In fact that deadline is what kicked me into doing all this. Are you sure I didn't mention it?
Need better title
I'll not be uploading a video of the current state, as there should probably be something surprising come the weekend, but the last couple of weeks have been spent finessing things somewhat.
There's sound - simple, but hopefully effective. After a couple of iterations, I have a two-channel mixer with one channel having envelope control.
Following alpha tester feedback (hi!), I've cobbled together a Perl script that calculates keyboard interference and come up with a different set of controls for player 2.
Using the same script to find sets of keys that work on the CoCo, the game will self-patch if it finds itself running on one. The combinations are pretty tortuous - on the CoCo, the joystick firebuttons conflict with many useful keys - but hopefully just about usable. I've roped another alpha tester in to see how it hangs together on real CoCos.
Finding the exit triggers an animation, and magic has entered the world. A lot of bugs are fixed, a lot remain.
But all in all - highly demonstrable! One might even call it playable (analogue joysticks aside for now). So I'll bring it along on Saturday, and hopefully there'll be enough free Dragon time to get an idea of how it works out for multiple players in practice.
Something worth trying for
The Dragon meetup in Cambridge was good fun. It was really great to put faces to names. I didn't stay nearly long enough to meet everyone, so hopefully another opportunity will roll around soon.
As usual, it was far more interesting finding out what other people were doing than showing off my own stuff, so only a few people actually played the game. And that was probably quite confused gameplay what with there being no instructions around. Ah well, next time perhaps a little sign with some background information...
But to progress! Since the last video, the really obvious main thing to appear is sound. Grunts & chirps, but hopefully effective grunts and nicely styled chirps. See what you think.
As mentioned in the previous update, there's actually two channels being mixed there: one sawtooth wave for the main effects and one square wave for the less defined things like monsters dying. The sawtooth wave has a form of envelope control (which, if you're interested, involves self-modifying code and picking out either NOP or LSRA from a table), which means beeps can have a nice "ramp up" sound to them.
Through the looking glass
Something else you can see is the option to pick PAL or NTSC. If you select NTSC, tiles are palette-shifted and various other bits adjusted so that you can play with a proper black background with artifacted colours. This is equivalent to the old Microdeal select screen where you chose Black or Green (or indeed Buff - I'm sure some people selected that) background.
There's a well-known foible of the NTSC CoCo 1/2 (and indeed Tano Dragon) that the VDG clock can fire up in one of two phase relationships with the colour subcarrier. Old games typically had you pressing RESET until a filled screen was the right colour, but as I'm doing palette shifting anyway, I've presented an interstitial screen to select which set of palettes are used.

Here's what the game looks like in NTSC. There's no green in this mode, so you have to put up with the Ranger being blue, but otherwise it all looks pretty decent:
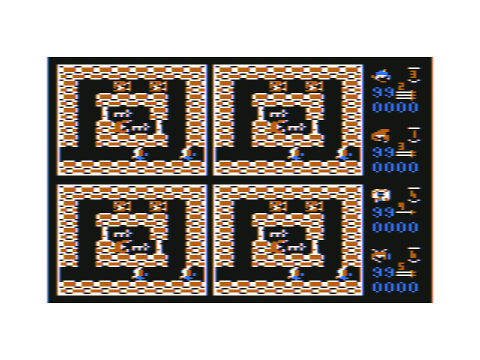
Strong and Stable gaming
So by this point I'm pretty convinced that my code is the business and feel it's time to take it to real hardware to reassure myself of just how brilliant I am. Initial polling is good - I finally get my Dragon out of the loft and the game runs well.
Then I take the game to Cambridge and try it with real joysticks for the first time (thanks, Stew). All seems ok with a digital gamepad-style controller, but with analogue joysticks there are some real problems. They're not responding to my treatment of the DAC very well.
Back at home, I fish my CoCos out of the loft too, and oh dear: it would appear my assumptions are all wrong. Real hardware rejects my proposal, and the keyboard layout I've calculated for the CoCo doesn't work at all. Move right and instead it uses magic! Many attempts to fix this fail, and I spend a good few hours thinking that a CoCo version might be dead in the water.
At this point stupid analogies start to fail outright: I'm pretty sure I can't just make a deal with a bunch of crazies to force people to accept the broken state of things, so I have to do some real work and figure out what's wrong.
A lot of schematic-staring later (and soliciting help from IRC - thanks, William Astle) and I finally notice a tie between the two PIAs that the CoCo uses for RAM size detection. On the Dragon 64, one side of that is configured as an output and is used to select which BASIC ROM is mapped. On the CoCo, if that's configured as an output, it affects one column of the keyboard. I add a small extra patch for the CoCo and phew! All working as expected3.
But if I had much hair, it would be time to sweep the floor right now!
Thanks also to Mysoft, whose CoCo FastLoader made testing iterations of that much more pleasant.
As an aside, I still seem to have a problem with my CoCo 3: any key in column 7 is unrecognised if another key in the same row is pressed at the same time. That seems very unlikely to be intentional, because it means you can't press SPACE at the same time as any of the cursor keys, and many games are going to be relying on that. This extra problem really didn't help my initial investigation!
If you're interested, here's a small tool (provided as a WAV) that just shows the row/column joins being made as you press keys. You can use it to watch matrix ghosting behaviour too: try holding Shift + '/' + '.' simultaneously.
Of course this rather raises the question of why this problem didn't show up in emulation. More work to be done there, I'm sure.↩
So when can I have a Beta, then?
Soon! This is my current list of real blockers before I throw it out there for beta testing:
- Add the chalice to level 25
- Make completing the game possible
- At least a stab at making analogue joysticks more usable
- Redraw partially-overwritten objects when monsters die
From then it'll probably be a case of ensuring balance (where possible), fixing rough edges and adding purely decorative features.
Phew! That was a long one. Go have a cup of tea.
Sincerest form of flattery?
Yeah, that'll do.
After initially pushing this update out, I went and looked at Stewart Orchard's blog for Return of the Beast. Turns out he's also doing some palette shifting in his project, and his routine is about half the size of mine (same basic approach, but more clever noticing bits that have already been cleared). So I've, ahem, delicately lifted it.
Beta 1
It's now in theory possible to complete the game. It's probably stupidly hard (kinda accurately replicating the original in that regard), needs a lot of presentation work, and may still have stupid bugs. But as far as I can tell it's good enough to not be too embarrassing to release, so have at it!
In the spirit of releasing stuff, here's the Perl script I used to vet key combinations for the different platforms - making sure they didn't conflict with each other:
But if you think I'm doing any more work on it today with the sun beating down like this, you've got another think coming.
The icing on the world
With Beta 2, I've fixed a few "features" and prettied things up a bit. It's all looking nearly done, so maybe now's a good time to exercise the old critical self-awareness.
Immediately putting that off for a moment, here's some stuff that changed (some of this might have been in Beta 1, but I didn't write about that. Which only goes to show what they say about putting things off: extra long blog post alert!).
Sticks
Joystick handling seems to be a lot better. Looking at what I'd written, I wasn't even using the analogue thresholds I thought I was. It tests out on the only analogue joystick I can find at the moment: a Tandy Deluxe hooked up to a CoCo 2.
Stones
I used to have a set of twelve stone graphics to form the walls on subsequent levels. In Cambridge, Stewart (it's that man again) mentioned in passing that having the graphics change is good, as it gives players a bit of visual reward for getting to the next level. I started to feel a bit stingy as I was repeating the same set of twelve for the second half of the game, so I've spent a bit of time drawing another twelve. Where possible, they look at least a little like the Beeb originals, but sometimes I couldn't recreate the effect, so I've gone for something that works better in the available palette.
Level 25 gets its own "stone".
Breaking bones
(Would make some sort of sound, I guess?).
The sound core is still two channels mixed, but waveform is selectable for both (square or sawtooth), and volume of both is controllable in four steps (if you include "off"). This is a sort of "envelope" control, albeit manually varied as it stands. Here's the main fragment playing loop:
As usual with this sort of thing, the whole thing is contained within the Direct Page, and virtually every part of it is self-modifying code.
Because audio is switched off so the DAC can be used to read the joysticks, there's also always going to be a low frequency component whenever sound is played. Hopefully that just adds to the charm...
Where you waking up today
When asked, literally nobody could tell what the boots of speed were supposed to be. Now, my attempt at recreating the original graphic was not amazing, but I'm not convinced even the original is very obvious. So bringing out the GIMP, I've tried my hand at a replacement. Given the amount of pixels available, I'm happier with this as a representation of boot-with-wings:

The chalice
The main thing the betas bring is a completable game. For this I needed to get the chalice on screen in the final room. The chalice is 2x2 tiles in size, and is animated. I toyed with various ways I might simply repurpose existing code to do this: maybe make the chalice be a substitute for doors in this level (there are no others)? Hm no, doors aren't animated. How about just have four extra objects? Nah, I'd have to expand the object table just for this one level.
So in the end I special-cased it. If you're on level 25 and in the right room, some extra code draws a chalice on the screen (and updates it to animate). Not exactly clever coding!
(And of course, for a while there my logic failed and a chalice was appearing in that room on every level. Now you know why there's a Beta 2.1!)
I've actually never completed the original, and Youtube videos only ever showed one player getting to the chalice, so I'm not sure what the mechanics are for triggering the end game. I've decided on something I think is quite neat (and for all I know it's how the original works!): all players still alive must surround the chalice and be attempting to move into it. Gives people one final moment of cooperation. Well, I liked it.
There's not yet any sort of end-game animated sequence. I think I want to make this a bit different to the original, as it seems a little... well, let's say long.
State of the Union
Westminster continues to pillage the nations and regions to feed an insatiable London metropo... wait, that's not what this bit's about. Ahem. I mean, how does this conversion stack up against the original?
Well, we have lower resolution graphics with fewer colours, and sound has to be generated by the CPU in between everything else so inescapably, it's worse in almost every measurable aspect. But that's not very positive, is it? Let's redefine "original" slightly!
While mostly concentrating on the BBC version I played at school, I've mentioned a couple of times that there was also a release for the Electron. Being a cut down version of the Beeb, ports to & from the Electron weren't supposed to be too difficult. It's got the same 32K of RAM, however, it lacks the BBC Micro's sound chip, and RAM accesses use a 4-bit system (or so it says here).
Graphics
That second bit makes the Electron slow. If Dunjunz on the Electron were to use the same video mode as the Micro version, it would take twice as long to perform any updates to the screen. So instead, for the Electron, a mode with the same resolution but reduced palette is used - four colours, in fact.
So it has us beat in terms of resolution, but we're on a par for colours. That's a slight win for the Electron, but I'm going to claim a win on aesthetics for two reasons. First, I have stats windows - the Electron version just prints sequences of numbers underneath the play area. Second, the mode used in the Electron doesn't have that "free" animation (MODE 2 flashing colours), but I've manually animated tiles to replicate the look of the Micro version.
I've also created a suitably-scaled version of the font used on the Beeb. The Electron just used a system font for its menus and exposition. And hey: the boots, man. Look at 'em.
Speed
Somehow, even having to mask every tile onto the screen (as the tiles are not a whole number of bytes wide), the Dragon code still does it faster. While this will in part be due to the 6809's better indexed addressing modes, I'm at a loss to explain quite why the original is so slow. Speed-wise, this conversion ends up being a little faster even than the BBC version. Two for me, I think.
Sound
How about sound? Bit of a mixed bag here. The Electron doesn't have envelope control, but it can still set a sound going and just leave it playing while it does other things, and the sounds are crisp and clear. With no sound chip4 I have to generate it all manually. I'm grudgingly going to give the Electron a point.
No sound chip as of the now; there are motions towards widely available expansion carts that we might soon start to consider standard.↩
Control
Finally, how does it all play? Really, how well do the controls work? Well, jury's still out on this one. The Dragon keyboard is too small to get four people onto, and I'm reasonably sure I couldn't easily come up with even one more set of keys that didn't conflict with the other two players anyway, so joysticks are a necessity for players 3 & 4.
The analogue joysticks typical of the Dragon do not control this sort of game well. But adaptors for Atari compatible digital joysticks are common, and indeed it plays a lot better using one of those big old waggly Quickshot style sticks.
I took a punt on a couple of Sega Megadrive controllers on eBay, but it turns out that Megadrive (that's Genesis to Americans) controllers aren't quite as Atari-compatible as a quick search let on, and I'll have to cobble together a further adaptor to try them out. I'll let you know.
Are you done yet?
In summary, I think this rewrite is going to sit between the two original versions5 in terms of features, and for the most part feel nicer than the Electron version. I'm pretty happy with that. I did have it in mind that I could enhance it still further using the extra RAM of a Dragon 64, but suspect any such ideas might be a while in the realising!
Let's ignore the Master version for now.↩
I can still remember
What is this strange looking file? It seems like nothing written of in our lore, yet somehow it seems familiar to me.
Oh yes, I was writing up the development of Dunjunz, wasn't I? So some time has passed (cough), and I now have something I'm happy to call a Release Candidate. With no horrendous bug reports, this will become the proper "official"6 release.
Oh, I remember why I've not written anything until now. To capture a video with sound, I have to install PulseAudio (and then purge it once done). If you know how to make SimpleScreenRecorder record ALSA output, please let me know! But for you, dear reader, I shall temporarily subject myself to its dubious charm.
As official as rewriting something without anyone's permission can be, I suppose.↩
My god, it's full of betas
Reading up, it seems I last bothered to write anything was some time after Beta 2, so here's a quick summing up of what's changed since then:
- Lots of experimentation with joystick control
- Added easy mode
- Various bug fixes
- Behaviour fixes
- New sound core
- Title screen with music on 64K machines
- Requisite scrolly message
- Lots of packaging work
Joysticks
The game plays fine with digital controllers, and pretty ok with self-centring analogue sticks, but was really tricky with the original style of Dragon analogue non-self-centring stick. The problem is diagonals: it's really easy to hit them accidentally, and Dunjunz always checked one axis before the other.
I tried a couple of approaches and eventually settled on a system where the player will always turn if a gap is available in the axis orthogonal to current direction of travel. It's not great, but it does make things a little easier to handle. Digital controls are still highly recommended.
Easy mode
Much feedback noted the very high difficulty level. Part of this was a bug that would cause you to lose health more rapidly than you should when "following" a monster, but mostly, it's because the original was just as hard. For easy mode (optional), various changes are made to the game:
- Monsters do less damage
- Monsters are easier to kill (though they get harder again on later levels)
- Energy drainers take fewer shots to destroy
And the most visible change: doors and keys can be of two different colours - thus slightly increasing your chance of knowing you have the right key for a door. This was surprisingly easy to add. Extra object types represent the different coloured keys and doors, and which type something is just alternates while reading through the initial level data.
It was important to update the status window with the right colour key too!
I think these changes combine to make the game more fun, and Steve Bamford (Bosco) confirms that it fits solo play very well. While it really is supposed to be a game for a group of people, I have to acknowledge that single-player is probably how it's going to be tried most, so easy mode is the default.
Hey hey 64K
I had some fun with this. After a bit of reading about the 76489 sound chip used in the BBC Micro (and, importantly, Master), I came up with a music player that approximated its sound. Then I hacked the Unix version of Beebem to print out sound register writes along with timing information. This was easily parsed to produce a sort of "Playola" for my music player, and it sounded pretty good!
This simple conversion was not exactly suitable for inclusion in the game, however: it took all 64K of RAM to represent the whole tune. I'm far too lazy to go through and break it down into notes and envelopes, etc., so instead I wrote a little bit of Perl that broke it instead into chunks just under 1s long (exact duration determined through experimentation). Bodge fans will enjoy this: I dumped each pattern to a separate file, then used md5sum in a bash script to identify repeats.
The result fits in about 16K, and compresses even further. Perfect! Or rather: Good Enough!
In the process, I came up with a fun trick for generating square waves. The general wavetable n-channel mixer technique is by now well known, but doesn't lend itself to different amplitudes without using quite a lot of extra RAM. I already knew I also needed a 24-bit counter, else the low frequency notes would sound really off. So here's a snippet of code for one channel of the player:
psg_c1off1 equ *+1
ldd #$0000 ; 3
psg_c1freq1 equ *+1
addd #$0000 ; 4
std psg_c1off1 ; 5
psg_c1off0 equ *+1
ldb #$00 ; 2
psg_c1freq0 equ *+1
adcb #$00 ; 2
stb psg_c1off0 ; 4
sex ; 2
psg_c1att equ *+1
anda #$00 ; 2
sta psg_c1 ; 4First, the lower 16 bits of the counter are incremented by the value calculated for a given frequency. So far so normal. Then the upper 8 bits are incremented similarly (including carry from last operation). This is done in the B register so that the top bit can quickly be used to generate either $00 or $ff using the SEX instruction. Finally, that is ANDed with the desired amplitude, which can be varied as much as you like without needing another table per value.
In real code, instances of this per channel are summed together, et voilà: squares suitably pushed! I'm calling the player "Jenky", for really good reasons.
Tape loader
The last couple of weeks has mostly been getting it packaged up and tested.
The extra code for 64K machines needs to be loaded somewhere. By far the easiest approach to this is to load the extra stuff first, copy it to high RAM if it's there, then load the main game. Easy, but not satisfactory: there's quite bit of data being pulled in that, on a 32K machine, will just be thrown away. On tape, that's quite an annoying waste of time! So I want the process to be: load main game, then if there's 64K available load the extras.
Now, even keeping the main part compressed while we do so, there isn't actually enough space left in the lower 32K of RAM to hold the extras, so some shuffling of data is going to be required. One technique would be to manually exchange the data between low and high RAM, load the second part, then swap them back.
I'm sure that would have worked, but I decided to try being "clever" and use a hardware feature of the SAM to do this for me: when 64K is detected, the loader will copy the small amount of data necessary for the ROM tape routines to keep working into high RAM, then assert the "page1" bit and continue loading. With page1 selected, the SAM maps the second 32K of RAM to the lower address space. ROM continues to be available, and I can carry on using its tape routines.
And it worked just fine! Until I came to test it on a CoCo 3. The CoCo 3 doesn't have a SAM in it, it has a GIME. The GIME simulates quite a lot of SAM and VDG functionality, but doesn't support the page1 bit. D'oh!
Ok, no problem - what the GIME does have is some quite good MMU functionality, I'll just remap the upper RAM pages to the low addresses to simulate page1. Nice idea, but my first attempt doesn't work. I figured I'd just map the "default" pages that get used in map type 1 into the lower address space. Nope! A bit of virtual head-scratching on IRC, and William Astle points out that those default pages actually map the ROM when the GIME is simulating map type 0.
The fix was to map completely different pages into high RAM and map those same pages low while loading the extra part. Now I have a loader that seems to work on anything, even a CoCo 3.
And disk?
How annoying it is to have to distribute two disk images, one for the Dragon, one for the CoCo. So I've created a "hybrid" disk image. Thankfully, each system uses different tracks for their directory information and boot sectors.
In the allocation tables for each format, I've simply "allocated" the sectors used by the other format. Half the disk looks accessible to DragonDOS, RSDOS thinks the other half is free.
A bit of extra code, and I have BOOTable disks for each system. Nice!
Stick a bow on it
That's all now looking... well. Done. Weird. So at this point, no more changes! Unless there are bugs, of course. But what bugs can there be, eh? Don't answer that!7
I can't put it off any longer, I'm going to have to record a video... Here, have a shuftie! I'll not let the music play through completely: you get the idea, why not go download it yourself and give it a listen?
Please do answer that. Really, if there are bugs it would be cool to get them sorted. Who knows, maybe you'll end up in the scrolltext...↩
And we're done!
So last night I did the final testing - making sure it loaded from disk & tape on all the real hardware I have to hand - and made the final 1.0 release. That's it! With some last-minute tweaks to the scrolltext, and a spruced up Dunjunz homepage, I'm declaring it "done". Enjoy!
I've covered a lot of it before, but I'll probably get some thoughts down as a retrospective soon and then that'll be the last thing I add to this page, too.
At least until one or other of the sound cards in development for the Dragon/CoCo "wins" and it's time for "Dunjunz+"!

Wait, there's more!
Three years on from the original release, let's look back on what happened next.
By the time of the 2017 Cambridge meet-up, I only had a prototype ready to show people. A couple of months later, the game was finished. But the meet-up was good fun, and we'd already agreed to do it again: "same time next year". There was a very strong urge to do something special with the finished version by then.
Cometh the meet, cometh the "Anniversary Edition" (v1.1). Here's what git log says happened:
- Complete UI overhaul - see below.
- Music optimisations. Seems that a slightly tweaked pattern length yielded big results here - the later, better version actually ends up quicker to load.
- And of course, lots of other optimisations and bug fixes.
The first release was all supposed to be visually similar to the BBC Micro version (with a "fun" scrolltext similar to that on the Electron), with it's fancy crooked font and what-not. But I didn't like the way the mode had to switch to show the game messages.
In the end I decided to keep the screen fairly constant, always showing the character profiles down the right hand side. The main play area can then be reused for option selection and messages. Building on this new interface:
- Palette switching can be done at any time from the options screen, not just once on program load.
- The controls for each character are shown on the options screen.
- When you activate a character, it animates on the options screen.
- Wait long enough, and it'll cycle through a couple of credits screens.
The biggest enabler for the new interface was a new font. Well, a new old font: I fleshed out the script-like one used on the original's title screen. The character order was specially chosen to encode the fancy long descenders into the bytes. I think the end result looks pretty fancy!
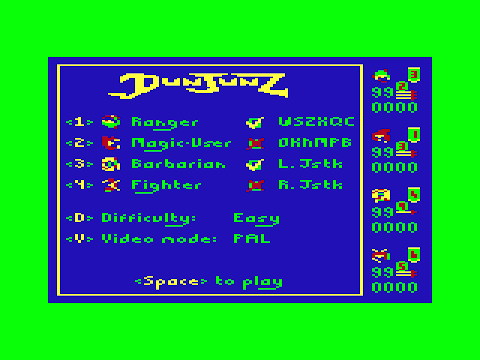
All in all, it comes across as far more professional-looking than the 2017 version. Still lacked that "special something" for the meet, though.
Vanity press
Reader, I made tapes.

Yeah man, tapes!
Ok, I didn't make them, I found companies online: Tapeline Ltd made up custom length blue shelled cassettes from a supplied WAV. Then Band CDs printed the inlays onto nice card from a double-sided PDF - they even pre-creased the folds! Both companies were super quick and the results are excellent all round. I do recommend! I printed the labels myself - can you tell?
I set the the inlays with LaTeX. A little bit tricky: each folded panel needed to be slightly smaller than the one before it, then either side of the page had to line up exactly. The cover image was put together in the GIMP - good enough, but my major complaint there is that as soon as you have rotated some text, it's not text any more. Makes editing a complete pain.
The tapes were given away as freebies at the 2018 Cambridge meet-up. Not sure if people really knew what to make of that, but never mind.
If you want one for posterity, I still have a few left, available at cost (remember you can just download it). As a guide, I listed the cost of various forms of delivery in this Dragon Archive Forum thread. I doubt postage has gone up that much yet, but delivery to the E.U. is probably going to become much more hassle quite soon.
Only so vain
In the meantime, John Linville also designed his Games Master Cartridge. As you can read there, his intent is to provide complete saleable game cartridges with a built-in sound chip (the TI 76489 - exactly the chip in the BBC Micro, conveniently enough!) and up to 64K of bank-switched ROM. It's a great idea, but again, the fact I've adapted so many assets from Julian Avis's originals probably makes it unviable for John to make any money off it. There's also the issue with importing from the US: I don't begrudge the VAT, but you end up paying as much in "handling fees" as the thing is worth.
That said, if you have one of his developer kits, you can burn your own ROM - see Dunjunz - Games Master Edition for an image. Fancy sound effects, and even a tiny bit more CoCo 3 support in the form of palette setting.
In summary: breezes
I'm pretty happy with how this has all turned out. The game is what I wanted for the Dragon in the 80s. A few people even have a physical tape of it on their shelves (albeit totally vanity published). I learnt a bunch of stuff along the way, and any learning is usually good learning.
By the way. There are two known bugs in the Anniversary Edition. The first is that it needs Extended Color BASIC to load properly on the CoCo. That's probably fine, as I think it'll be quite rare that someone has a 32-64K machine but not have Extended BASIC. The reason? IRQs aren't enabled on the PIA, as TIMER only exists in ECB. To work around it, load by typing POKE65283,53:CLOADM instead of just CLOADM.
The second bug, I won't divulge - at least not yet - it doesn't affect finishing the game. See your name in lights here if you find it!8
I'd still love to hear from anyone that's managed to cajole others into playing co-op with them - that was definitely the most fun way to play at school. I'll list any reviews here, accepting that maybe they'll be a bit thin on the ground: we're not really back in the 80s, however much we may wish to escape 2020...
- Not a review really, but L. Curtis Boyle has included Dunjunz on his CoCo games list.
- Amigos Retro Gaming have done a review on The CoCo Show. They seem generally positive!
- Cue 50 different bug reports.↩
FIN